1同行回答
因为涉及到数据库的升级,在做升级之前最好先做好数据的备份,以防止数据的丢失。
按照用户需求制定升级方案,本次升级是社保业务数据库从x86服务器升级到Power740小型机,光纤交换机选用的是IBM B24,存储设备选用的是IBM V5000。原有的x86服务器及存储设备用于其它业务系统和OA使用以节约成本。
社保业务数据库升级项目主要包括主机系统、网络系统以及数据安全系统的系统集成。整个涉及如下设备和系统:
1、 IBM p740 小型机构建业务系统的数据中心的主机系统,通过配置双机集群软件 HACMP,构成高可用的集群结构;在集群上部署 ORACLE 数据库,并通过 RAC 组件把数据存储和处理工作分派给两台主机,实现负荷分担数据并发处理,提高系统的响应速度,达到数据海量吞吐。
2、IBM V5000及 两台IBM B24光纤交换机构建业务系统的 SAN 存储系统,存放社保业务数据、归档数据;并与 IBM DS4700 磁盘阵列之间通过数据同步模式实时的异地灾备,在出现异常情况时,最大限度地保障用户数据不会丢失和应用系统连续性。
3、IBM PC 服务器 IBM X3850,IBM X3650 作为社保局的功能服务器。IBM TS3200 磁带库接入到 SAN 存储系统中,通过 TSM 备份软件,对 ORACLE 数据及社保局其他重要数据作在线备份,确保重要数据的安全。
具体的数据升级和迁移可以参考以下操作步骤:
1、按照业务需求调试IBM V5000及IBM B24,在 IBM p740小型机安装Oracle。下面是V5000建议组网图: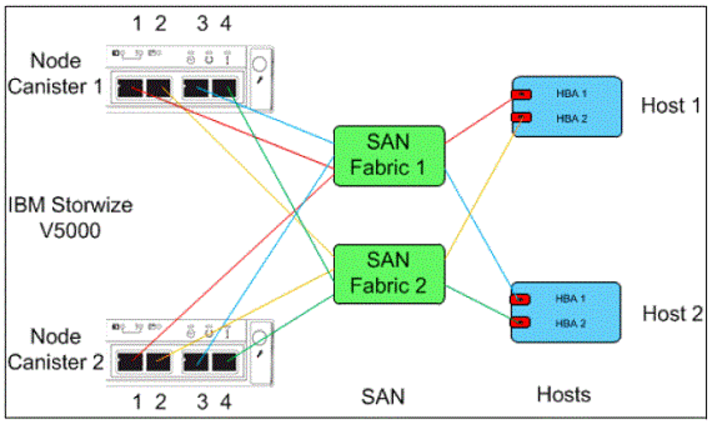
2、对目标Oracle数据库进行字符集AL32UTF8修改为ZHS16GBK。
3、备份原有数据库。
备份数据库有两种:1)使用PLSQL导出数据库;2)通过命令导出。一开始选用第一种,因为界面操作比较简单。不过发现导出的过程很多表都提示不存在,感觉出了问题。找开发确认一下,说还是用命令导出比较不容易丢失。所以改用命令导出。果然最后完全导出。
命令导出方法如下:
1)用管理员权限打开cmd命令窗口;
2)输入一下命令:exp,根据提示完成数据库导出。
3)在选定的路径中即可找到备份的数据库文件。4、导入数据库到目标服务器数据库。
命令导入方法如下:
1)用管理员权限打开cmd命令窗口;
2)输入一下命令:imp,根据提示完成数据库导入。5、验证新环境数据库数据的准确性、无效对象、无效索引等。
6、将应用服务器的数据库连接指向新的数据库。
7、重启应用系统。
8、验证业务系统的各项功能。
9、检查数据库日志是否有任何报错。
10、调试TSM备份软件。
下面是数据导入过程中经常出现的一些错误与解决方法:
创建数据泵目录并赋权:
create directory expdata as '/backup';
grant read,write on directory expdata to system;
修改后的导入脚本(添加红色标记参数,解决11g的一个Bug 8415620):
impdp system/XX directory=expdata dumpfile=zj2_%U.dmp logfile=zj2.log parallel=4 schemas=ZJ job_name=zj2 cluster=n
导入报错一
导入过程中碰到了一个11g相关的bug(Bug 8415620)
报错信息摘录如下:
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
ORA-31693: Table data object "XX"."XX" failed to load/unload and is being skipped due to error:
ORA-31640: unable to open dump file "XX.dmp" for read
ORA-19505: failed to identify file "XX.dmp"
ORA-27037: unable to obtain file status
IBM AIX Error: 2: No such file or directory
Additional information: 3
解决方法:
Cannot Run DataPump With PARALLEL > 1 On 11.2 RAC [ID 1071373.1]
Cause
From 11.2, DataPump new parameter CLUSTER is introduced.
CLUSTER : Default=Y
Purpose :
Determines whether Data Pump can use Oracle Real Application Clusters (RAC)
resources and start workers on other Oracle RAC instances.
Syntax and Description : CLUSTER=[Y | N]
Solution
To force DataPump to use only the instance where the job is started and to replicate pre-Oracle Database 11g release 2 (11.2) behavior, specify CLUSTER=N.
导入报错二
表空间不存在:
报错信息摘录:
Import: Release 11.2.0.3.0 - Production on Thu Jun 14 17:52:13 2012
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Data Mining and Real Application Testing options
Master table "SYSTEM"."ZJ2" successfully loaded/unloaded
Starting "SYSTEM"."ZJ2": system/ directory=expdata dumpfile=zj2_%U.dmp logfile=zj2.log parallel=4 schemas=ZJ job_name=zj2
Processing object type SCHEMA_EXPORT/USER
ORA-39083: Object type USER failed to create with error:
ORA-00959: tablespace 'DATA' does not exist
Failing sql is:
XX
解决方法:
创建一个表空间:
create tablespace DATA datafile '+DATA' size 10g autoextend on next 512m maxsize unlimited;
导入报错三
数据文件达到最大大小,无法自动扩展,导入作业挂起:
报错信息摘录:
ORA-39171: Job is experiencing a resumable wait.
ORA-01653: unable to extend table XX by 8192 in tablespace XX
解决方法:
为表空间XX添加一个数据文件,初始大小20G,设置为自动扩展:
SQL> alter tablespace XX add datafile '+DATA' size 20g autoextend on maxsize unlimited;