K8S生态之服务发现解析
当前, 云原生生态 已经成为全球各大厂商以及企业尤其是互联网企业技术选型、场景推广的一个重要参考标准。 云原生所代表的技术已经逐渐成为大家的共识,从一个虚无缥缈的概念逐渐演化成众多参与者的下一个技术战略储备。自然而言,承载业务需求的应用架构就会提及到微服务生态体系,以及其中最重要的分布式协作模式—— “Service Discovery”,即:服务发现。
在微服务体系架构中,我们通常所说的“服务发现”,指的是广义层面的描述,其主要包含两个最核心的模块:服务注册与服务发现。那么什么是“服务注册”、“服务发现”呢? 通常来讲,服务注册,指的是将提供某个服务的模块信息(通常是这个服务的 IP 和 Port )注册到某个公共的组件上去,例如: 微服务生态中的 Zookeeper、Eureka 以及 Consul 等等组件。其语法可描述为: NameServer—>register(newServer)。
而对于服务发现,其指的是新注册的这个服务模块能够及时的被其他调用者所发现。无论其操作状态为服务新增还是服务删减都能够实现自动发现。 其语法可描述为: NameServer— >getAllServer()。
针对上述概念的解析,其具体场景表现为:服务 X 调用服务 Y 时,需要通过服务发现模块找到服务 Y 的 IP 和 Port 列表,而服务 Y 的实例在启动时需要把提供服务的 IP 和 Port 注册到服务注册中心。一个典型的服务发现结构如下所示:

基于上述结构图,针对每一个 Service (如 X、Y、、、)包含多个实例,每一个实例包含对应的IP 和 Port,以方便对方调用。 逻辑上还是 Serivce X -> Service Y -> Service WV,但是 Proxy 或者 Service 帮助我们隐藏了细节,因此,基于应用服务角度,从 Service X 至 Service Y,我们能看到只不过是一个完整的服务,而非其他主机资源。
其实,从本质上讲,在微服务生态的发展历程中,其终极目标无非是为了将业务组件与非业务组件进行完全分离,使得每一个微服务能够独立且完整,其具体的实现细节将会被封装或隐藏掉,对客户端无感知。作为 Service Mesh 目前最流行的产品,Istio 使用了基于 Virtual Service 与 Destination Rule 来解决了服务注册与发现的问题,正在一步步朝向最终目标前进。
** 服务注册
截止目前,基于微服务生态体系流行的注册中心比较多,无论其基于何种语言,比较常见的有 Zookeeper、Ectd、Consul、Eureka 、Nacos 以及 Coredns 组件等。服务注册通常有三种:自注册、主动注册以及 第三方注册 。具体如下所示:
1、自注册,指的是服务提供方在启动服务过程中通过将提供服务的 IP 和Port 发送到注册中心,并通过心跳方式维持健康状态。当服务下线时,自己把相应的数据删除。目前,典型场景就是基于使用 Eureka 客户端发布微服务。
2、主动注册,与第三方注册方式比较类似,主动注册方式是指注册中心和调度或发布系统路由互通,主动同步最新的服务 IP 列表信息。典型的场景为基于 Kubernetes 生态体系中,Coredns 订阅 Api Server 数据。
3、第三方注册, 第三方注册 是指 存在一个第三方的系统或平台专门负责在服务启动或停止过程中向注册中心增加或删除服务数据。 典型的场景例如基于 Devops 系统或容器调度系统主动调注册中心接口注册服务。
接下来,我们再解析下“ 服务发现”相关架构体系, 具体可参考如下内容。
** 服务发现
在真正发起服务调用前,调用方需要从注册中心拿到相应服务可用的 IP 和 Port 列表,即服务发现。 服务发现从对应用的侵入性上可以分为两大类:
1、SDK-Based 这类的服务发现方式,需要调用方依赖相应的 SDK ,显式调用 SDK 代码才可以实现服务调用,即对业务有侵入性,典型例子如 Eureka、Zookeeper 等。
2、DNS-Based DNS 本身是一种域名解析系统,可以满足简单的服务发现场景,如双方约定好端口、序列化协议等等。但是,这远远不能满足真正的微服务场景需求。近几年,基于 DNS 的服务发现渐渐被业界提及并进一步推广与落地。
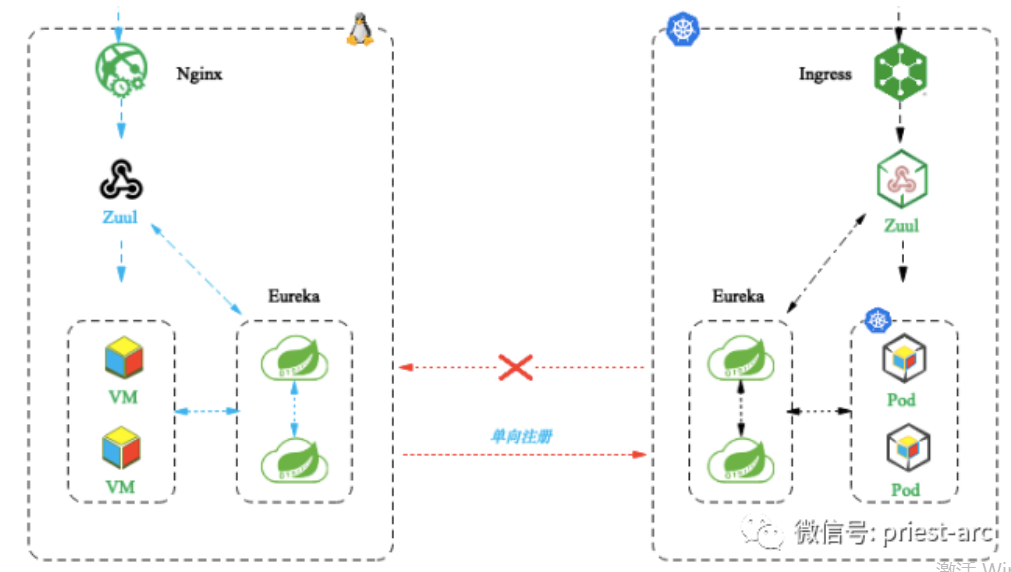
以上为站在微服务角度针对“服务发现”原理机制及场景进行解析,接下来,我们将基于容器生态并对其进行补充。
在 Kubernetes 生态中,我们通常借助 “Service” 概念-对象 来实现服务之间的互访,具体为在一组提供服务的 Pod 之前创建一个稳定的网络端点,并为这些 Pod 进行负载分配。具体如下所示:

基于上图所述,右侧的 Pod 可能会因为容器服务的伸缩、更新、故障等相关场景,其数量将会发生变动,而 Service 会实时对这些变动进行跟踪、监测。与此同时 Service 的名称、IP 和 Port 却不会因为 Pod 的任意变动而产生变化。 从本质上讲,我们可以将 Kubernetes Service 抽象为 Front-end (前端)和 Back-end(后端)两个核心部分。针对 Front-end 部分,其稳定可靠,名称、IP 和 Port 在 Service 的整个生命周期中都不会改变,因此,意味着无需担心客户端 DNS 缓存超时等问题。针对 Back-end 部分, 其包括一组符合标签选择条件的 Pod, 其属性 为动态更新, Pod 往往会因为各种客观原因进行动态调整。因此,在实际的业务场景下,需要借助负载均衡机制来维持服务访问的无感性。基于上述的解析,我们以 Node Port Services 为例,简要描述请求从群集外部访问服务的最基本方法。节点端口是保留在群集中每个节点上的端口,可通过该端口访问服务。具体如下图所示:

在 Kubernetes 1.12 以及后续的版本 ,为了满足服务注册及发现这一需要,每个 Kubernetes 集群都会在 Kube-System 命名空间中用 Pod 的形式运行一个 DNS 服务,通常称之为集群 DNS。 集群 DNS 基于 CoreDNS,以 Kubernetes 原生应用的形式运行 。其所实现的注册流程,具体如下所示:
1、 向 API Server 用 POST 方式提交一个新的 Service 定义
2、此请求需要经过认证、鉴权以及其它的准入策略检查过程之后才会放行
3、Service 得到一个 ClusterIP(虚拟 IP 地址),并保存到集群数据仓库
4、在集群范围内传播 Service 配置
5、集群 DNS 服务得知该 Service 的创建,据此创建必要的 DNS A 记录。
从某种意义上来说 ,CoreDNS 实现了一个控制器,会对 API Server 进行监听,一旦发现有新建的 Service 对象,就创建一个从 Service 名称映射到 ClusterIP 的域名记录。这样 Service 就不必自行向 DNS 进行注册,CoreDNS 控制器会关注新创建的 Service 对象,并实现后续的 DNS 过程。通常, DNS 中注册的名称为 metadata.name,而 ClusterIP 则由 Kubernetes 自行分配。基于上述配置,当 Service 对象注册到集群 DNS 之中后,其就能够被运行在集群中的其它 Pod 发现。
当 Service 的前端创建成功并注册成功后,Service 对象依 据 Label Selector 标签列表把流量分发至后端的 Pod 列表中,因此,只有符合列表条件的 Pod 才能够获取到前端服务的请求,具体可参考如下示意图:

基于上述结构图,在实际的业务场景中,Kubernetes 会自动为每个 Service 创建 Endpoints 对象。Endpoints 对象的职责就是保存一个符合 Service 标签选择器标准的 Pod 列表,这些 Pod 将接收来自 Service 的流量。
通常,针对 Kubernetes 集群中某两个相互互访的应用,例如: w eb-x 和 w eb-y。 要使用服务发现功能,每个 Pod 都需要知道集群 DNS 的位置才能正确使用它。因此每个 Pod 中的每个容器的 /etc/resolv.conf 文件都被配置为使用集群 DNS 进行解析。因此, 如果 web-x 中的 Pod 想要连接到 w eb-y 中的 Pod(前提条件: w eb-x 知道目标服务的名称 ),就得向 DNS 服务器发起对域名 w eb-y-s vc 的查询并获取 w eb-y-s vc 的 ClusterIP(VIP)。此时,将会往此 IP 发送流量请求,由于 ClusterIP 所在的网络被称为 Service Network ,因为没有路由,所有容器把发现这种地址的流量都发送到了缺省网关(名为 CBR0 的网桥)。这些流量会被转发给 Pod 所在节点的网卡上,基于此场景, 节点的内核修改了数据包 Header 中的目标 IP,使其转向健康的 Pod。
基于上述所述,在实际的容器环境中,我们在创建 新的 Service 对象时,会得到一个被称为 ClusterIP 的 虚拟 IP。 服务名及其 ClusterIP 被自动注册到集群 DNS 中,并且会创建相关的 Endpoints 对象用于保存符合标签条件的健康 Pod 的列表,Service 对象会向列表中的 Pod 转发流量。 与此同时集群中所有节点都会配置相应的 Iptables/IPVS 规则,监听目标为 ClusterIP 的流量并转发给真实的 Pod IP。与此同时,若此 Pod 基于 Service 访问其他的 Pod ,先进行 Core DNS 查询请求,将 Service 名称解析为 ClusterIP,然后将流量发送给位于 Service 网络的 ClusterIP 上,再次,基于缺省网关进行流量转发以及内核的调整,最终使得流量分发至可路由的扁平的叠加网络中的健康 Pod 列表之上。
综上所述,基于容器 K8S 生态中 “服务发现“机制的相关解析,本文到此为止,大家有任何问题或建议,可以随时留言、沟通。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞2作者其他文章
评论 0 · 赞 1
评论 4 · 赞 1
评论 4 · 赞 2
评论 4 · 赞 1
评论 6 · 赞 1
添加新评论0 条评论